Contact Us
WhatsApp
+65 8012 2467
Email Us
contactus@thopps.com
Contact Us
WhatsApp
+65 8012 2467
Email Us
contactus@thopps.com

Learning Series: Understanding Visual Perception in Surveillance Systems
Understanding how cameras interpret scenes differently from human vision
When people begin working with video analytics, one assumption appears almost immediately:
“If I can clearly see it in the camera feed, the system should understand it too.”
At first, this sounds reasonable.
After all, both humans and surveillance systems are looking at the same video.
But this assumption quietly breaks many computer vision systems — because cameras and humans do not perceive the world in the same way
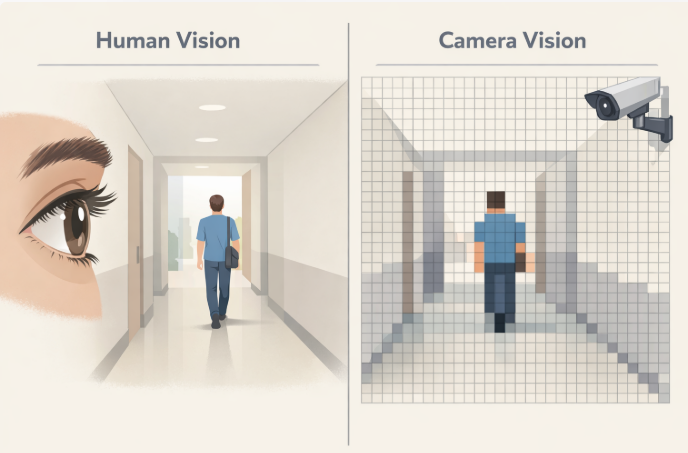
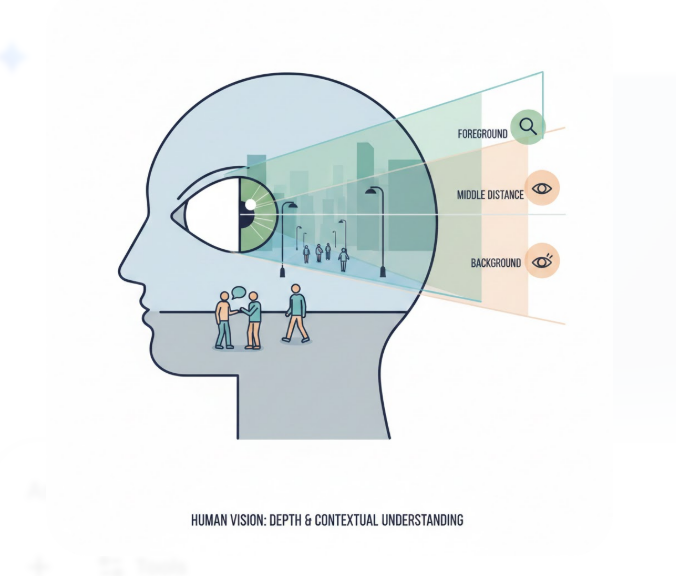
When a human watches a video, the brain does a lot of work automatically.
We understand:
Depth, context, and meaning are inferred instantly.
We are not just seeing pixels — we are interpreting a scene.
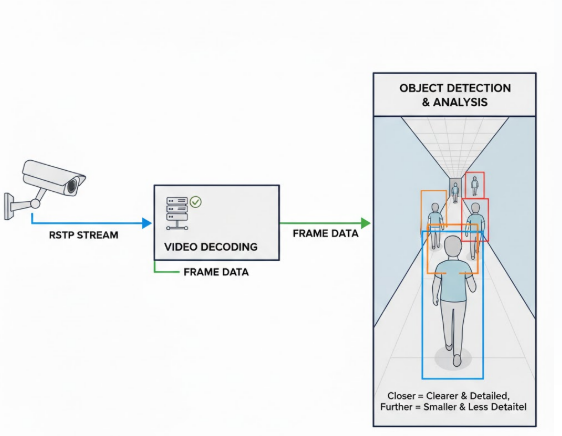
A camera does not understand scenes.
It captures light and converts it into a flat matrix of pixel values.
Each pixel only contains information like:
There is no depth information.
No awareness of distance.
No understanding of objects.
From the system’s point of view, everything exists on a two-dimensional surface.
This is the first major limitation of video perception.
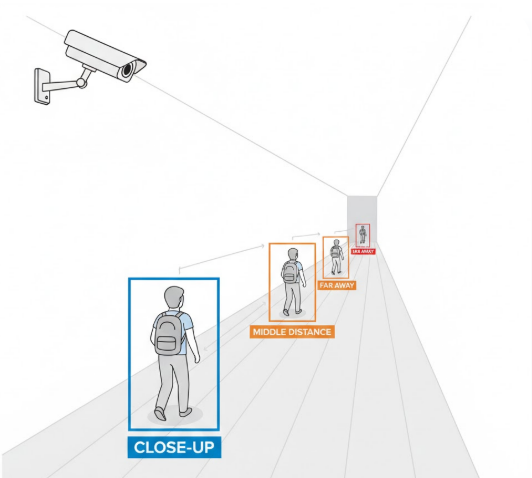
In the real world, a person walking away from us does not physically shrink.
But inside a video frame, their pixel representation becomes smaller.
As distance increases:
For a computer vision model, this change looks like the object itself is transforming.
This is why detection confidence often drops as people move farther from the camera — even though nothing meaningful changed in the scene.
The limitation is visual, not intelligent.
n many real surveillance pipelines — built using tools like:
this effect appears constantly.
Objects near the camera are detected reliably.
Objects farther away appear less stable.
Well-designed surveillance systems account for this by observing patterns over time instead of relying on a single frame.
This allows perception noise to be absorbed before any higher-level reasoning takes place.
The same environment can appear very different depending on camera placement.
A top-mounted camera separates people clearly.
A side-angle camera introduces overlap.
A low-angle camera exaggerates size and hides detail.
Even with the same model and configuration, behavior can vary.
Not because the AI behaves inconsistently — but because each camera produces a different visual perspective of the same scene.
Before behaviour analysis or intelligent reasoning begins, surveillance systems must operate on imperfect visual input.
Cameras do not capture reality — they approximate it.
Modern surveillance platforms are designed with this understanding, using time, context, and layered reasoning to build reliable interpretation from imperfect perception.
This is why intelligence is built above vision — not inside the camera itself.
Cameras don’t misunderstand the world — they simply perceive it differently.
Understanding this helps explain why intelligent surveillance systems are designed the way they are.
In the next article, we’ll look at why video feels continuous, even though it’s actually processed frame by frame — and why that matters.
Next in Series : The Illusion of Continuous Video