Contact Us
WhatsApp
+65 8012 2467
Email Us
contactus@thopps.com
Contact Us
WhatsApp
+65 8012 2467
Email Us
contactus@thopps.com


Learning Series: Agentic Development: A New Way to Build Software
The hidden risks of agentic systems
We’ve spent years building systems where AI generates responses.
Now, we’re building systems where AI makes decisions and takes actions.
That shift sounds subtle — but it fundamentally changes how systems fail.
A wrong answer is recoverable.
A wrong action is executed.
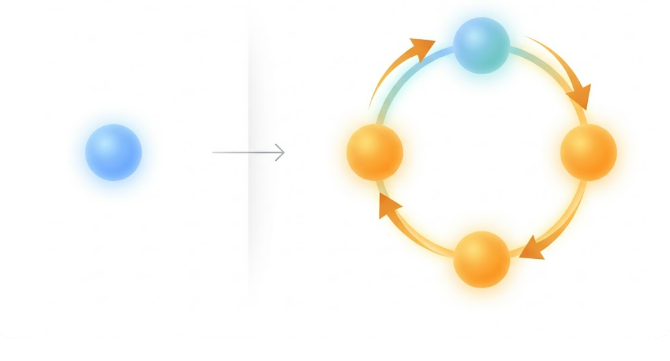
Traditional LLM applications are mostly stateless:
Agentic systems introduce a loop, often based on the ReAct pattern:
Reason → Act → Observe → Repeat
Here, the model:
This creates a stateful, evolving system.
And that’s where new failure modes emerge.
LLMs don’t verify truth — they optimize for likelihood of tokens.
In isolation, hallucination is manageable.
In a loop, it becomes dangerous.
A typical chain looks like:
This leads to what can be described as error propagation across iterations.
The system doesn’t just fail once — it drifts over time.
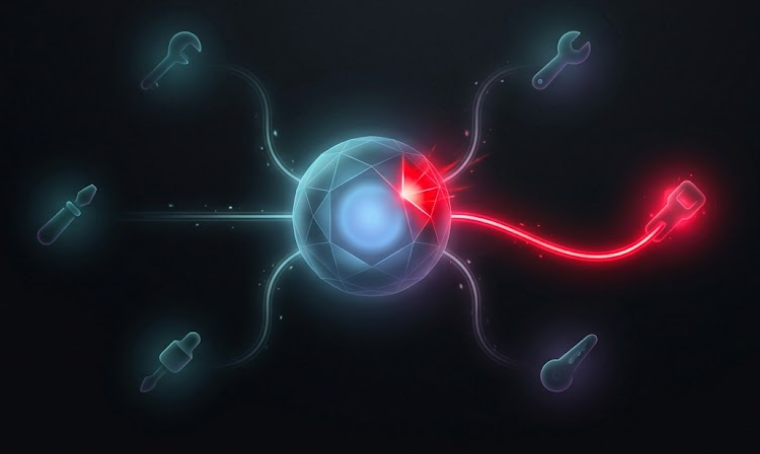
Modern agents rely on function/tool calling frameworks:
Tool selection is not deterministic — it’s inferred by the model.
This introduces:
For example:
The agent is not executing logic — it is predicting which logic to execute.
ReAct-style systems require:
Without them, agents may:
This is often caused by:
The system appears active — but produces no meaningful progress.
Agents optimize for interpreted goals, not actual intent.
A prompt like:
“Detect suspicious activity”
is underspecified.
The agent must internally define:
This leads to:
In practice, this is a form of:
specification ambiguity → behavioral divergence

The real risk of agentic systems is not intelligence — it’s autonomy with side effects.
When agents are allowed to:
Without constraints, small errors can escalate into:
This is especially critical in:
An incorrect action is no longer local — it becomes system-wide.
Agentic systems combine three difficult properties:
Individually, each is manageable.
Together, they create systems that are harder to predict, test, and debug.
You’re no longer debugging functions.
You’re debugging decision-making processes over time.
Agentic systems require a different engineering mindset.
Instead of asking:
“What should this system do?”
You need to ask:
“What happens when it does the wrong thing?”
Practical safeguards include:
The biggest shift isn’t that AI can reason.
It’s that we’re allowing it to:
select actions and execute them inside real systems.
And that changes the cost of failure.
In agentic systems, failure is no longer a bad response — it is a decision carried out in your architecture.
If you’re building with agents, the real question isn’t:
“How capable is this system?”
It’s:
“How does it behave when it’s wrong?”