Contact Us
WhatsApp
+65 8012 2467
Email Us
contactus@thopps.com
Contact Us
WhatsApp
+65 8012 2467
Email Us
contactus@thopps.com


Learning Series: Understanding Visual Perception in Surveillance Systems
Previous: https://varsity.thopps.com/why-cameras-see-differently-than-humans
Why surveillance systems don’t actually “watch” video — they analyse frames.
When we watch a surveillance feed, it feels smooth.
People walk naturally.
Objects move continuously.
Nothing appears broken or jumpy.
Because of this, it’s easy to assume that surveillance systems observe video the same way humans do.
But what feels continuous to us is actually a carefully reconstructed illusion.
Human vision is remarkably good at filling gaps.
Even when information is missing, our brain automatically connects moments together.
We don’t notice pauses.
We don’t notice missing frames.
We simply experience motion.
This ability allows humans to understand activity even under poor lighting or low-quality video.

To a surveillance system, video is not motion.
It is a sequence of still images — frames — captured at fixed intervals.
At 25 or 30 frames per second, the camera records individual snapshots of reality.
Everything between those snapshots is not captured at all.
The system never “sees” movement.
It only sees change between frames.
Motion must be inferred.
Every video system samples reality.
Frame rate determines how frequently those samples are taken.
When sampling is sparse:
A hand gesture, a quick turn, or a brief entry can occur entirely between two frames.
To a human observer, it was obvious.
To the system, it never happened.
This is not a flaw — it’s the nature of temporal sampling.
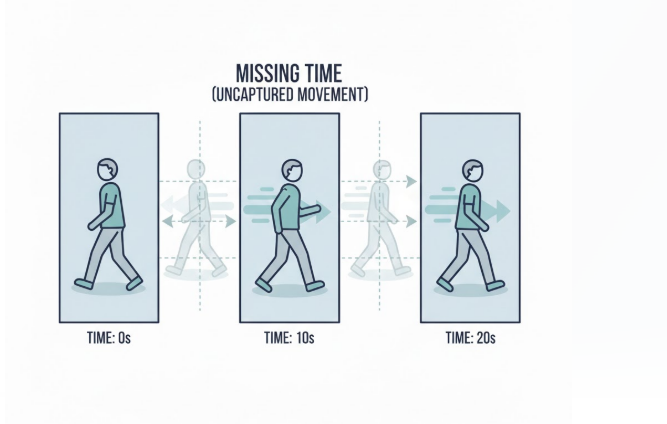
Consider a real surveillance scenario.
A person briefly steps into a restricted area and exits within a second.
At 10 frames per second, the system captures one image every 100 milliseconds.
If the person enters and exits between two capture moments, the event leaves no visible trace.
The system didn’t ignore it.
It simply never observed it.
This is why intelligent surveillance does not rely on single-frame interpretation, but evaluates activity over time.
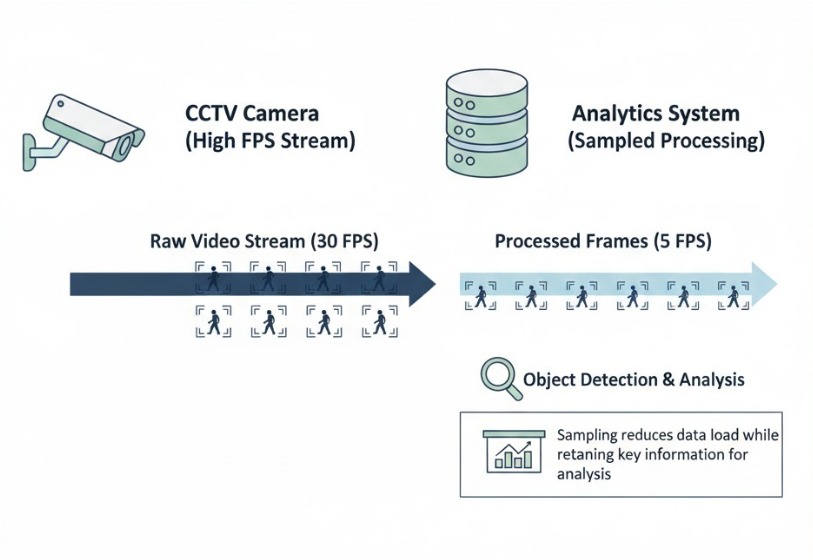
In real deployments, cameras and analytics engines rarely operate at the same frame rate.
A camera may stream at 30 FPS, but analytics pipelines often process fewer frames to manage compute cost.
In practice:
This design is intentional.
Processing every frame would increase cost, latency, and power consumption without proportional benefit.
Well-designed systems focus on meaningful patterns, not exhaustive observation.
It’s natural to think that increasing FPS will eliminate missed events.
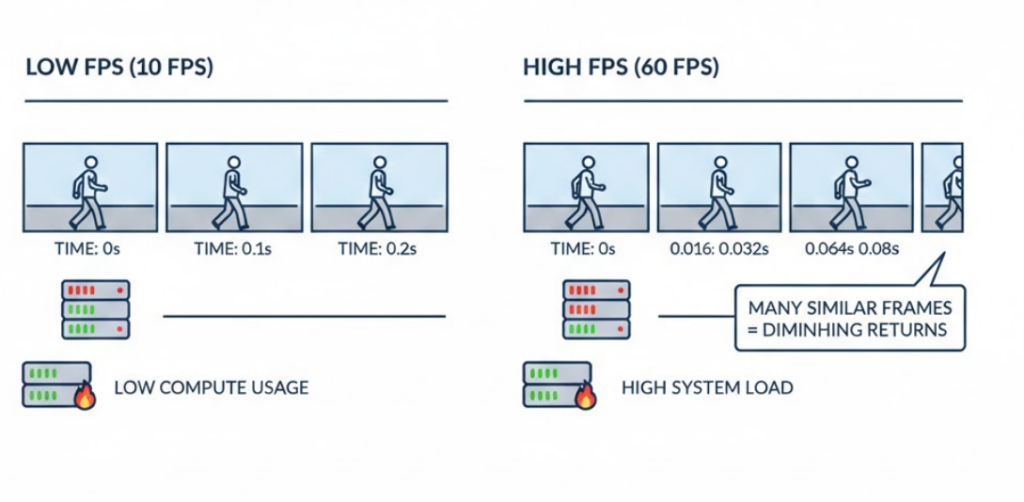
In reality, higher frame rates introduce trade-offs:
Beyond a certain point, additional frames add redundancy rather than clarity.
That’s why most production systems prioritize temporal reasoning over raw frame density.
Understanding over speed.
Since motion is not directly recorded, systems reconstruct it logically.
By comparing how objects appear across frames, analytics engines estimate:
This works extremely well for sustained activities like walking, loitering, or queuing.
Very brief actions may still be missed — and systems are designed with that expectation.
The goal is not perfect observation, but reliable interpretation.
Once video is understood as fragmented, the importance of time becomes clear.
Time allows systems to:
Rather than reacting instantly, surveillance platforms accumulate evidence across seconds.
This approach reduces false alerts and increases confidence.
Systems are not slow — they are deliberate.
Many design decisions in video analytics become easier to understand once we accept one truth:
Video is incomplete by nature.
Frames capture moments, not continuity.
Recognizing this explains why intelligent systems rely on duration, repetition, and patterns instead of instant reactions.
They are designed to reason carefully over partial observations.
Video may feel continuous to us, but surveillance systems work with fragments of time.
Understanding this helps explain why modern video analytics relies on patterns and duration rather than instant reactions.
In the next article we’ll look at something even more subtle — why pixels themselves are never truly stable, even when the scene appears completely still.
Next in Series: Why a Still Scene Is Never Truly Still