Contact Us
WhatsApp
+65 8012 2467
Email Us
contactus@thopps.com
Contact Us
WhatsApp
+65 8012 2467
Email Us
contactus@thopps.com

Learning Series: Foundations of Smart Surveillance
Previous: https://varsity.thopps.com/smart-camera-vs-smart-surveillance
Detection, Tracking, and Behaviour — and why seeing is not the same as understanding
When people first work with computer vision, they usually start here:
A camera feed.
A model.
Bounding boxes moving on screen.
It feels intelligent.
But behind that smooth animation is a very important limitation:
The model only understands one frame at a time.
And intelligence doesn’t live in frames.
It lives in time.
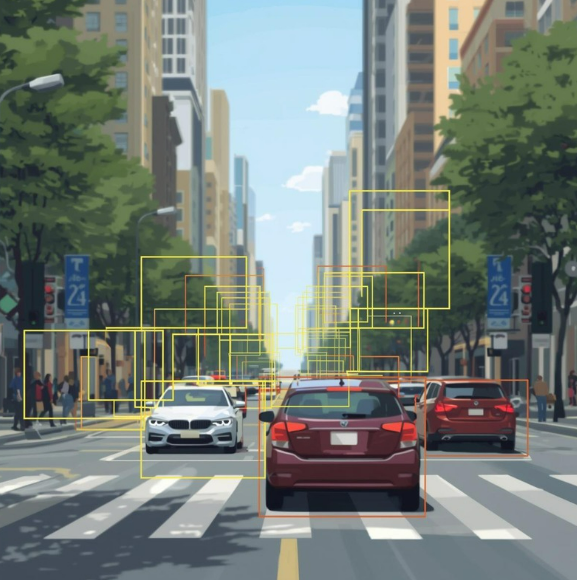
Object detection models like YOLO, SSD, or Faster R-CNN work in a very specific way.
They take:
Image → Neural Network → Bounding boxes + labels
Each frame is processed independently.
That means:
To the model, these are three unrelated images.
There is no concept of:
This is why detection models are called stateless.
They don’t remember anything.
They are excellent at answering:
“What objects exist in this image?”
But completely blind to:
“What is changing?”
And change is the heart of intelligence.
Tracking exists to solve one problem:
How do we know that an object in frame N
is the same object in frame N+1?
This is harder than it sounds.
So trackers combine multiple ideas.
Most modern trackers use three core signals:
Together, this creates something powerful:
a persistent ID
So instead of:
We now have:
This single idea unlocks massive capability.
Now the system can compute:
Tracking turns images into motion data.
But motion alone still doesn’t mean understanding.
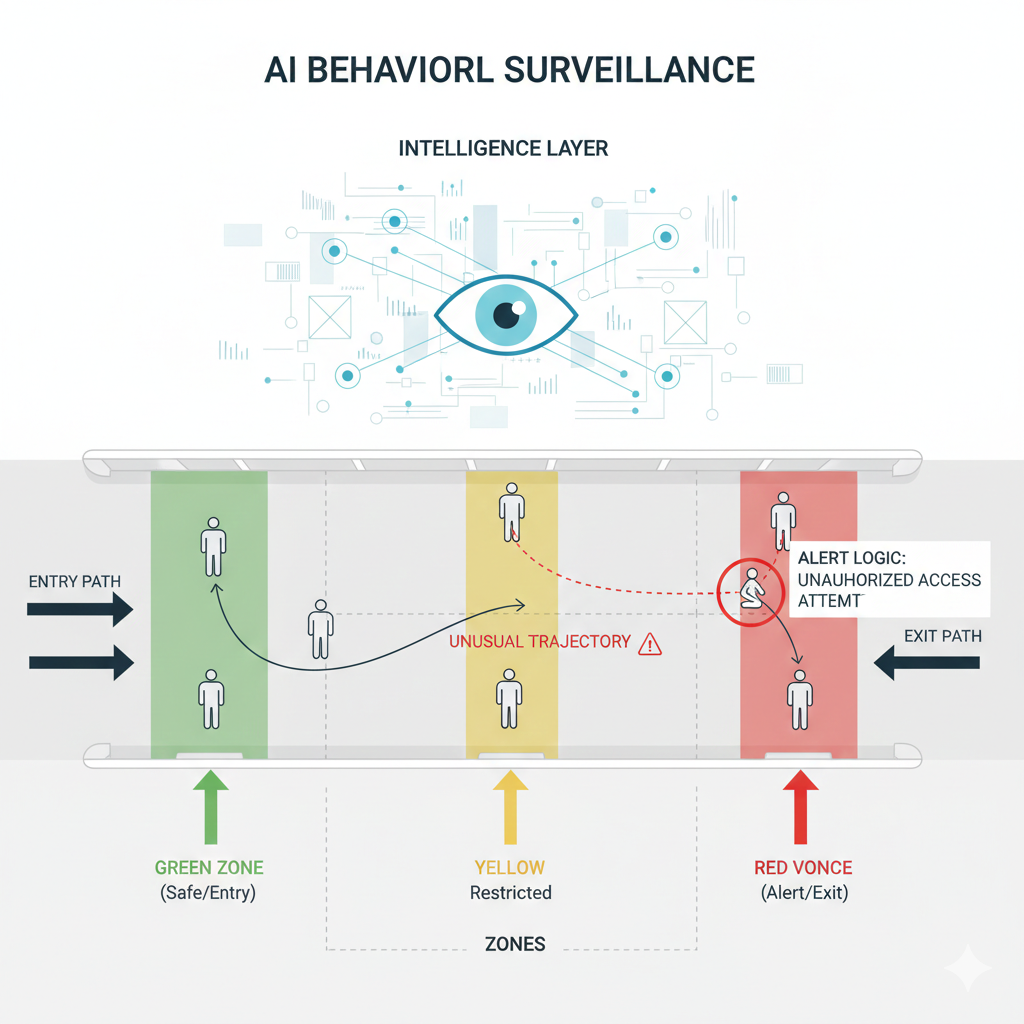
Behaviour analysis is where AI stops being visual and starts becoming logical.
At this level, the system is no longer asking:
“What do I see?”
It asks:
“What pattern is forming over time?”
Technically, behaviour is built using:
Example:
Person #12:
position at t1 → outside door
position at t2 → inside door
time gap from Person #11 → 1.3 seconds
That combination triggers a conclusion:
Possible tailgating event.
No new neural network needed.
Just structured reasoning.
This is why behaviour systems often look like:
Detection feeds tracking.
Tracking feeds behaviour.
Each layer depends on the previous one.
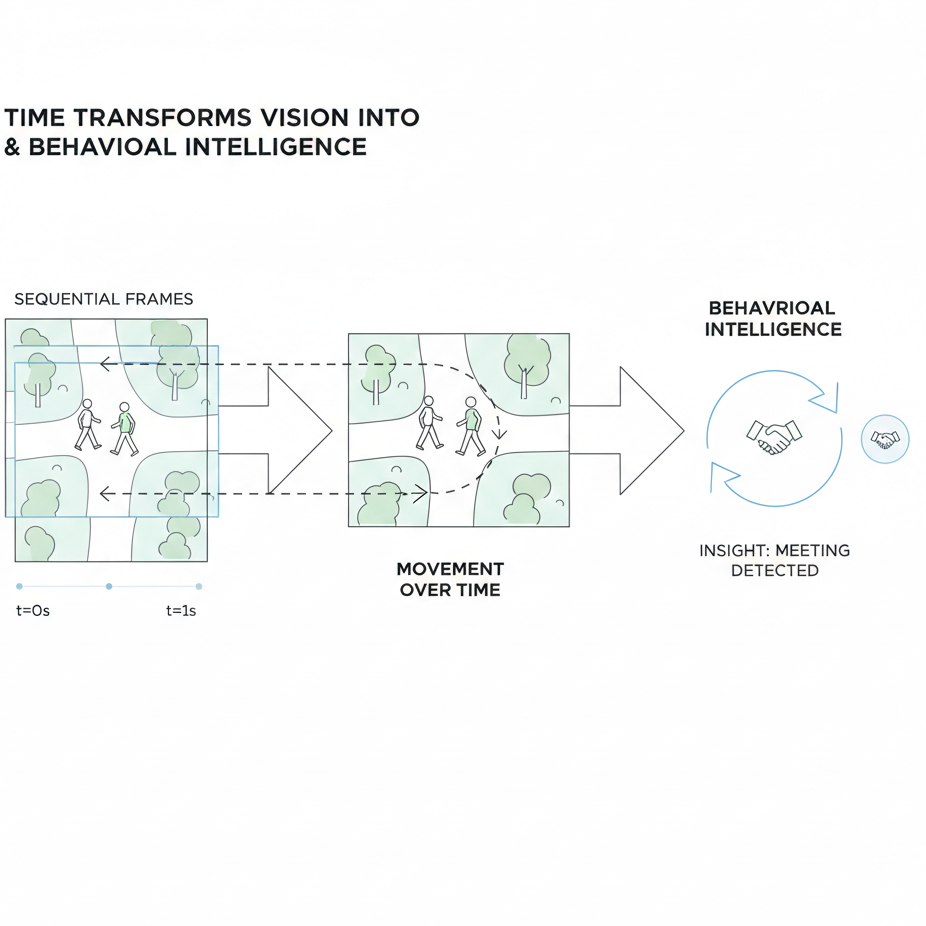
Without time, vision is static.
With time, vision becomes dynamic.
Behaviour systems use time to detect:
Examples:
None of these can be detected in a single frame.
They only appear between frames.
At a deeper level, AI vision systems transform data like this:
Pixels ↓ Objects ↓ Tracked identities ↓ Trajectories ↓ Events
This transformation is the real intelligence.
Not the bounding box.
The event.
Because humans don’t think in pixels either.
We don’t say:
“I see a rectangle moving.”
We say:
“Someone is entering.”
“That looks unusual.”
“Something just went wrong.”
That’s behaviour understanding.
Many systems stop at detection because:
But detection-only systems struggle with:
They shout too often — and understand too little.
Real intelligence doesn’t react fast.
It reacts correctly.
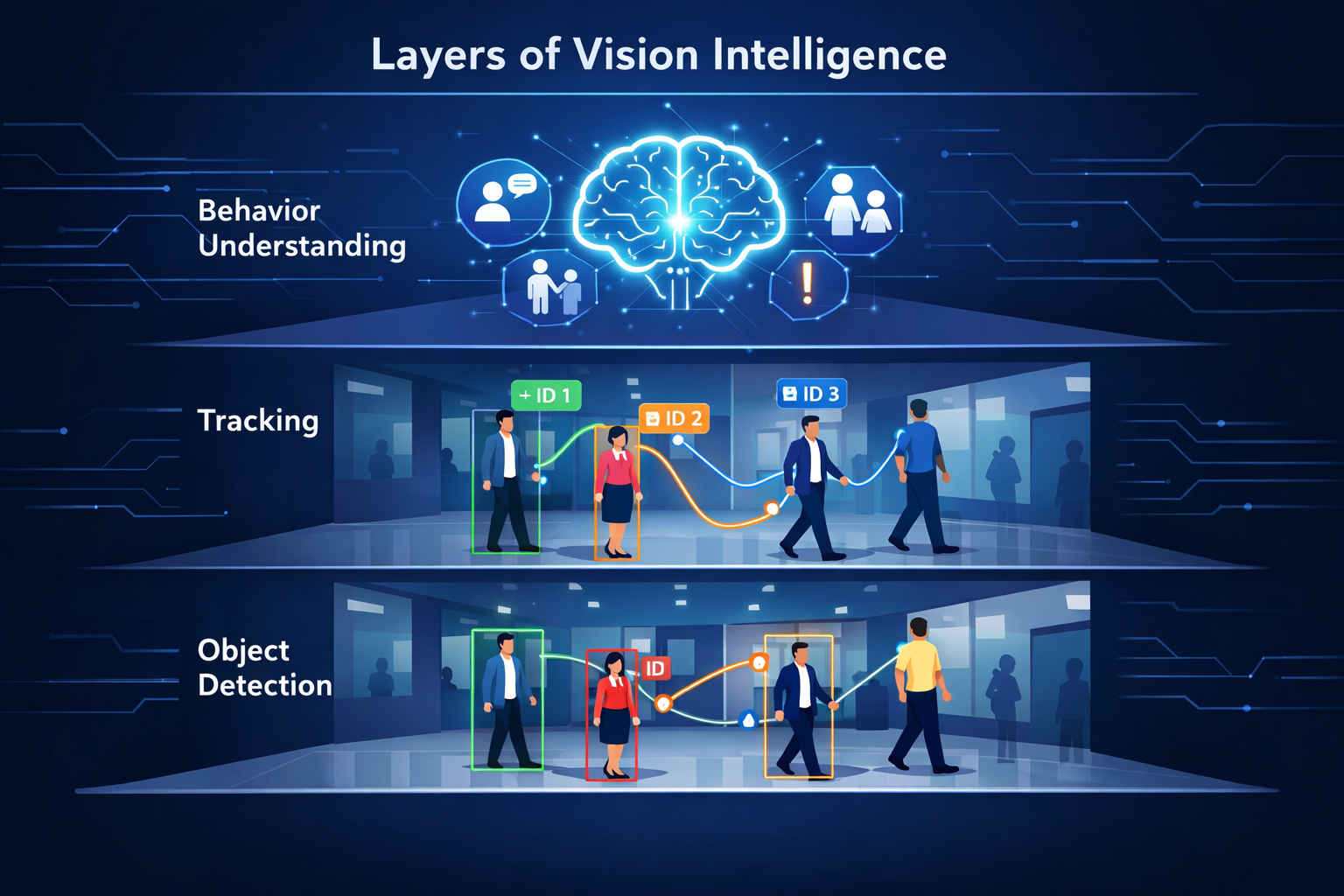
Detection teaches AI how to see.
Tracking teaches AI how to remember.
Behaviour teaches AI how to think.
That’s the real learning path in computer vision.
And once you understand this layering, something clicks:
Intelligence is not a model.
It’s a pipeline.
A pipeline that slowly turns vision into meaning.
Detection, tracking, and behaviour form the layers of vision intelligence — but none of them work in isolation.
What truly connects them is time
In the next article, we’ll explore why time matters more in AI surveillance — and how duration, frequency, and patterns are what transform movement into real understanding.
Next in Series: From Moments to Meaning: The Importance of Time in AI Vision