Contact Us
WhatsApp
+65 8012 2467
Email Us
contactus@thopps.com
Contact Us
WhatsApp
+65 8012 2467
Email Us
contactus@thopps.com

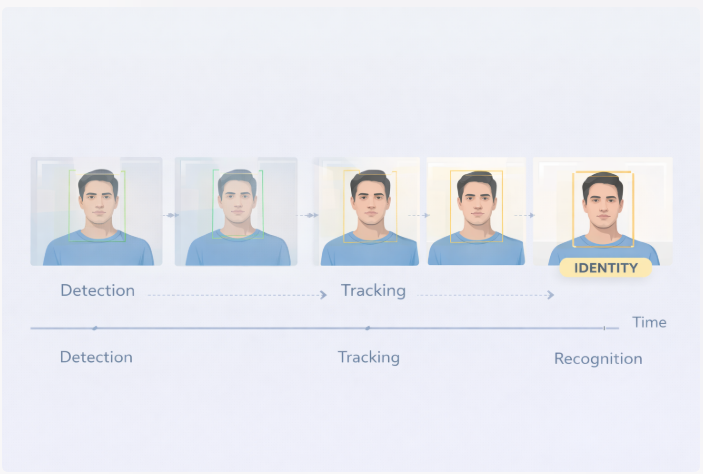
A practical reflection on detection, tracking, and identity across video.
When I started building a face detection and recognition pipeline, the idea felt simple.
Detect a face.
Recognize who it is.
But once the system moved from static images to a live video stream, I realized that identity behaves very differently over time.
I built the initial pipeline using InsightFace, which provided both face detection and high-quality face embeddings.
Detection worked reliably under good lighting and frontal angles.
Bounding boxes appeared cleanly, and embedding extraction felt straightforward.
At this stage, the system looked functional — faces were detected and embeddings were generated as expected.
Using InsightFace embeddings, I compared faces using cosine similarity.
The logic was simple:
In short tests, this worked.
But during continuous video, behavior changed.
The same person could be recognized correctly in one frame and missed in the next.
Sometimes the identity flickered.
Nothing crashed.
The system was doing exactly what I told it to do — just not what I expected.
That was the first major realization.
Face recognition models do not understand continuity.
Each frame is treated independently.
Even if the face stays in the same place, the embedding can shift slightly due to:
To the system, each frame is a fresh observation.
Identity does not persist by default.
This is where ByteTrack changed everything.
Instead of treating each detection independently, ByteTrack allowed the system to maintain consistent track IDs across frames.
Now faces weren’t just detections — they were tracked entities.
Recognition could be associated with a track instead of a frame.
This single change transformed how the pipeline behaved.
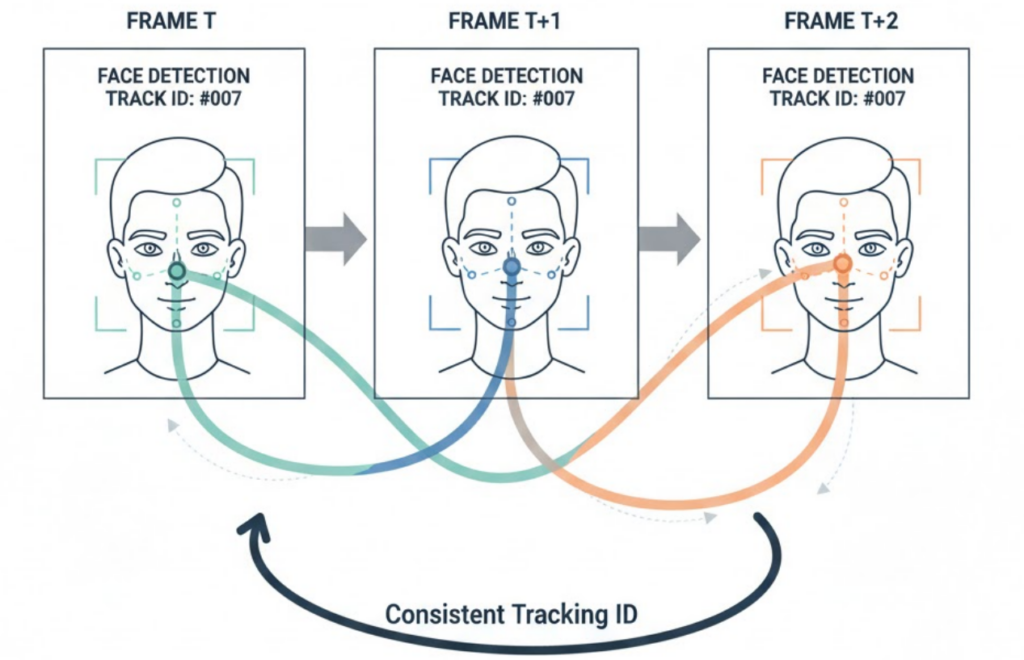
Once ByteTrack was introduced:
Instead of recognizing a face repeatedly every frame, recognition could happen once and then be reinforced over time.
The system stopped guessing constantly.
It started remembering.
Rather than deciding identity instantly, the system began observing.
Embeddings collected across a track were averaged or clustered.
If similarity remained consistent, confidence increased.
If results fluctuated, the system waited.
Identity became something that emerged — not something predicted instantly.
This felt much closer to how humans recognize people.
At this point, the pipeline clearly separated into three responsibilities:
Each component solved a different problem.
Trying to merge them earlier had caused instability.
Separating them brought clarity.
The biggest lesson wasn’t about accuracy.
It was about structure.
Recognition alone cannot handle video.
Tracking alone cannot assign identity.
Only when detection, tracking, and recognition worked together did the system become reliable.
The intelligence wasn’t inside the model.
It was in how the pipeline respected time.
Building a face detection and recognition pipeline taught me something important.
Identity does not exist in a single frame.
It exists across time.
InsightFace provided powerful visual understanding.
ByteTrack provided memory.
Together, they transformed momentary perception into continuity.
And that made all the difference.